
Efficient refactoring candidate identification
Period: March 2008 - December 2017
Table of Contents
- Motivation and Goal
1.1 Overview of the refactoring identification process - Method
2.1. Dynamic profiling-based refactoring identification
2.2. Multiple and independent refactoring identification
2.3. Two-phased search-based refactoring identification - Evaluation
3.1 Research questions
3.2 Data sets - RQ1. Effectiveness of the dynamic information
- RQ2. Efficiency of multiple refactorings
- RQ3. Efficiency of the two-phased approach
- Conclusion
- Papers
- Awards and Contribution
- Tools
Motivation and Goal
Recent research was focused on defining the cost-effective software refactoring process by suggesting the refactoring candidates that can maximize improvement in software design quality (e.g., maintainability). As the software is getting larger and more complex, it is harder to find the refactoring candidates because of the lack of resources in computing power and time. Therefore, we need a method to efficiently identify refactoring candidates for the large-scale software.
In this project, I propose the several new methods to improve the efficiency of the refactoring identification process.
Overview of the refactoring identification process
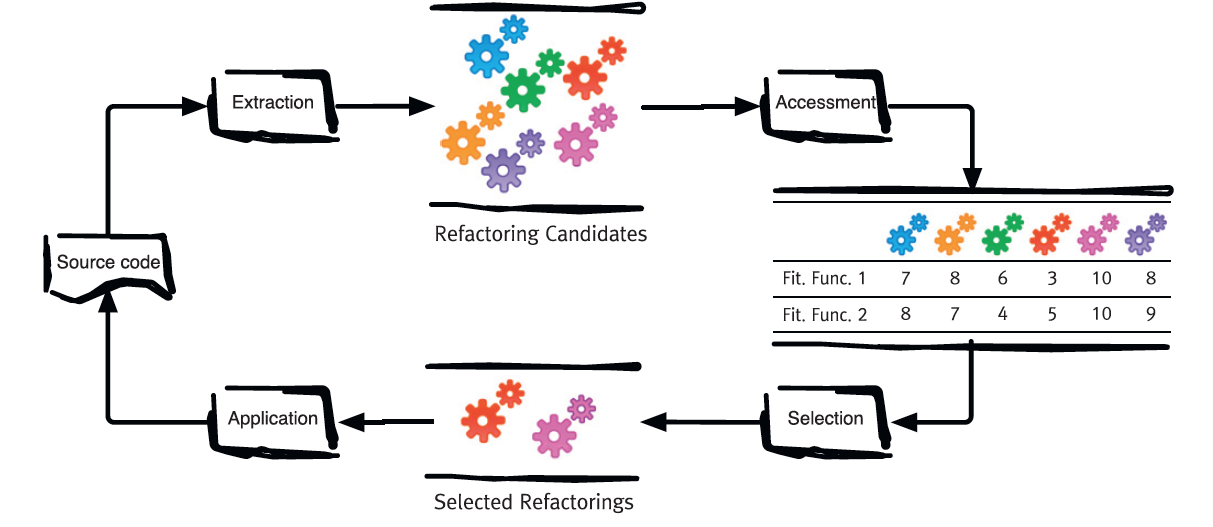
To identify refactoring sequence automatically, refactoring candidates are extracted and assessed using a fitness function measuring maintainability. Then, the refactoring that most improves the maintainability in terms of the fitness function is selected and applied. We use the stepwise approach which selects the most beneficial refactoring for each iteration of the refactoring process. This process is iterated until there are no more improvements. In this study, the refactoring candidates indicate the possible moves of methods to classes in the system (i.e., Move Method).
Method
Dynamic profiling-based refactoring identification [IST’2013]
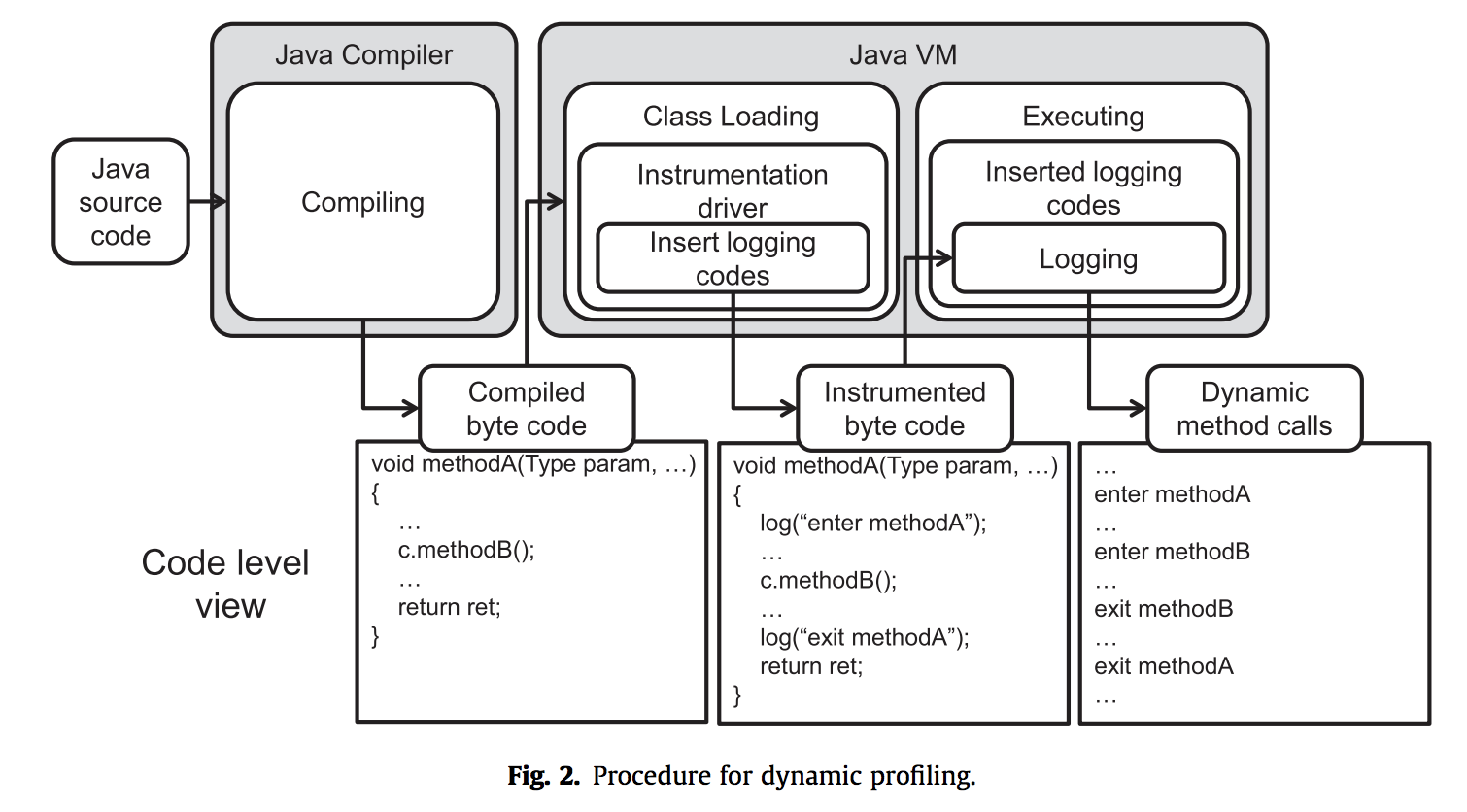 To identify the candidates in classes where real changes have occurred, I provided the method to use the
To identify the candidates in classes where real changes have occurred, I provided the method to use the dynamic profiling technique for finding the most frequently used functions based on the several scenarios of user behavior. Then, refactoring candidates are extracted to reduce the dependencies among the entities used in the most frequently used functions.
Multiple and independent refactoring identification [IST’2015]
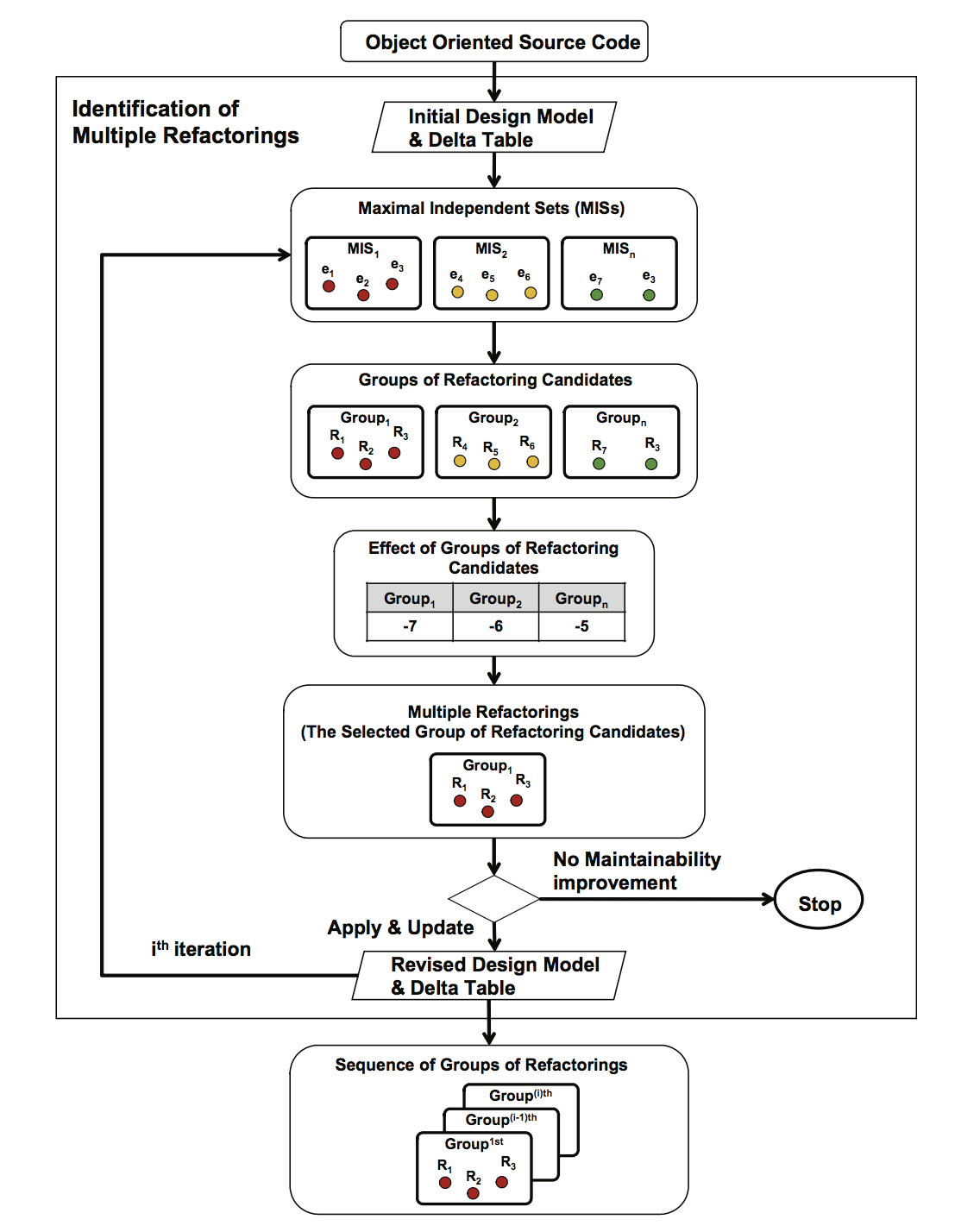 To find a sequence of cost-effective refactorings, I proposed the method for selecting
To find a sequence of cost-effective refactorings, I proposed the method for selecting multiple refactorings that have no dependencies each other and can be applied simultaneously based on the concept of maximal independent set (MIS).
Two-phased search-based refactoring identification [TSE’2017]
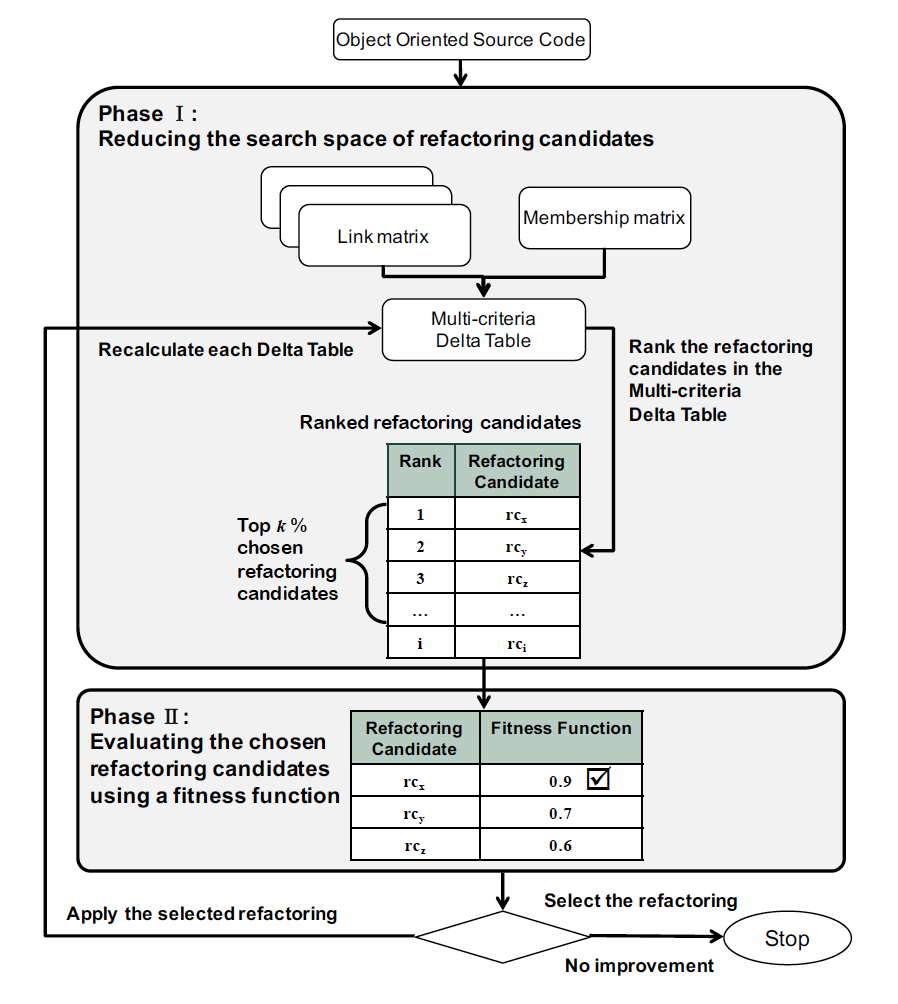
To reduce the search space of candidates to be examined, I suggested using the two-phase approach. In the first phase, the refactoring candidates that are more likely to improve maintainability are chosen using the Delta Table, lightweight and fast candidate assessment. In the second phase, only the chosen refactoring candidates are evaluated using a more complex and precise fitness function.
Evaluation
Research questions
RQ1. Is the dynamic information helpful in identifying refactorings that effectively improve maintainability?
RQ2. Do the multiple refactorings reduce the computational cost required to achieve the same maintainability?
RQ3. Is the two-phase assessment approach efficient?
How well does theDelta Tablecorrectly identify refactoring candidates that have actual higher maintainability metric values?
Data sets
Open source projects written in Java
- For RQ1 and RQ2
| Name (Version) | jEdit (jEdit-4.3) | Columba (Columba-1.4) | JGit (JGit-1.1.0) |
|---|---|---|---|
| Type | Text editor | Email clients | Distributed source version control system |
| Total # of revisions | 19501 | 458 | 1616 |
| Report period | 2001-09 ~ 2011-09 | 2006-07 ~ 2011-07 | 2009-09 ~ 2011-09 |
| Number of developers | 25 | 9 | 9 |
| Class # | 952 | 1506 | 689 |
| Method # | 6487 | 8745 | 5334 |
| Attribute # | 3523 | 3967 | 2989 |
- For RQ3 (for larger and more recent version)
| Project | Apache Ant 1.9.6 | JGit 4.1.0 | JHotDraw 7.0.6 |
|---|---|---|---|
| Type | Java application build tool | Distributed source version control system | Java GUI framework |
| Lines of code | 222,256 | 166,415 | 135,233 |
| Class # | 1,186 | 946 | 751 |
| Entity # (Method # + Field #) | 16,268 | 11,686 | 10,313 |
| Method # | 10,546 | 7,543 | 7,314 |
| Field # | 5,722 | 4,143 | 2,999 |
RQ1. Effectiveness of the dynamic information
Experimental design
To assess the capability of refactorings for maintainability improvement, we use the change simulation method. We assume that as the software becomes more maintainable, the less propagated changes would be occurred. Therefore, we inject changes and count the propagated changes on the three different approaches, and compare the reduced number of propagated changes.
| Comparators |
|---|
- Approach using dynamic information only (Dynamic) - Approach using static information only ( Static) - Combination of the two approaches ( Dynamic + Static) |
Evaluation measure
The efficiency of the identified refactorings can be evaluated by observing how fast the number of the propagated changes is reduced.
| Evaluation measure |
|---|
| Rate of reduction for propagated changes (%) |
The rate of reduction for propagated changes (%) can be calculated as:
{ Percentage of reduction for propagated changes(final) - Percentage of reduction for propagated changes(initial) } / # applied refactorings.
Results
The
average rate of reduction for propagated changesof theapproaches using dynamic information are higherthan that of the approach using only static information.
Number of impacted methods and classes for accommodating changes in
Columba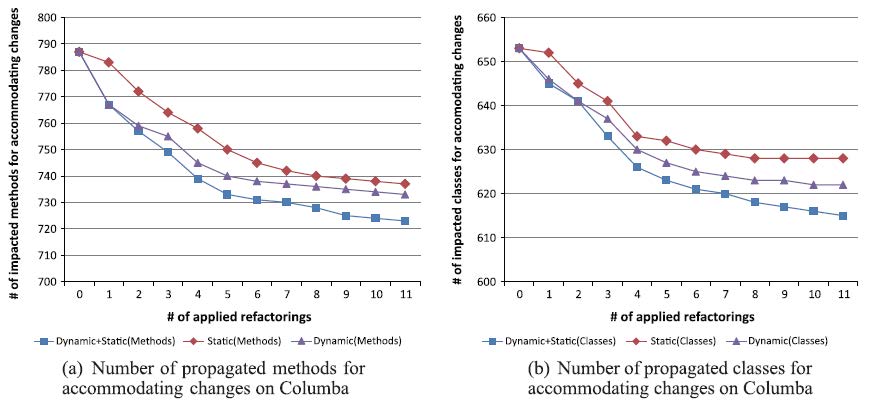 For example in
For example in Columba, the approaches using dynamic information reduce the number of propagated changesfasterthan the approach using only static information does.Percentage of reduction for propagated changes (%),Rate of reduction for propagated changes (%)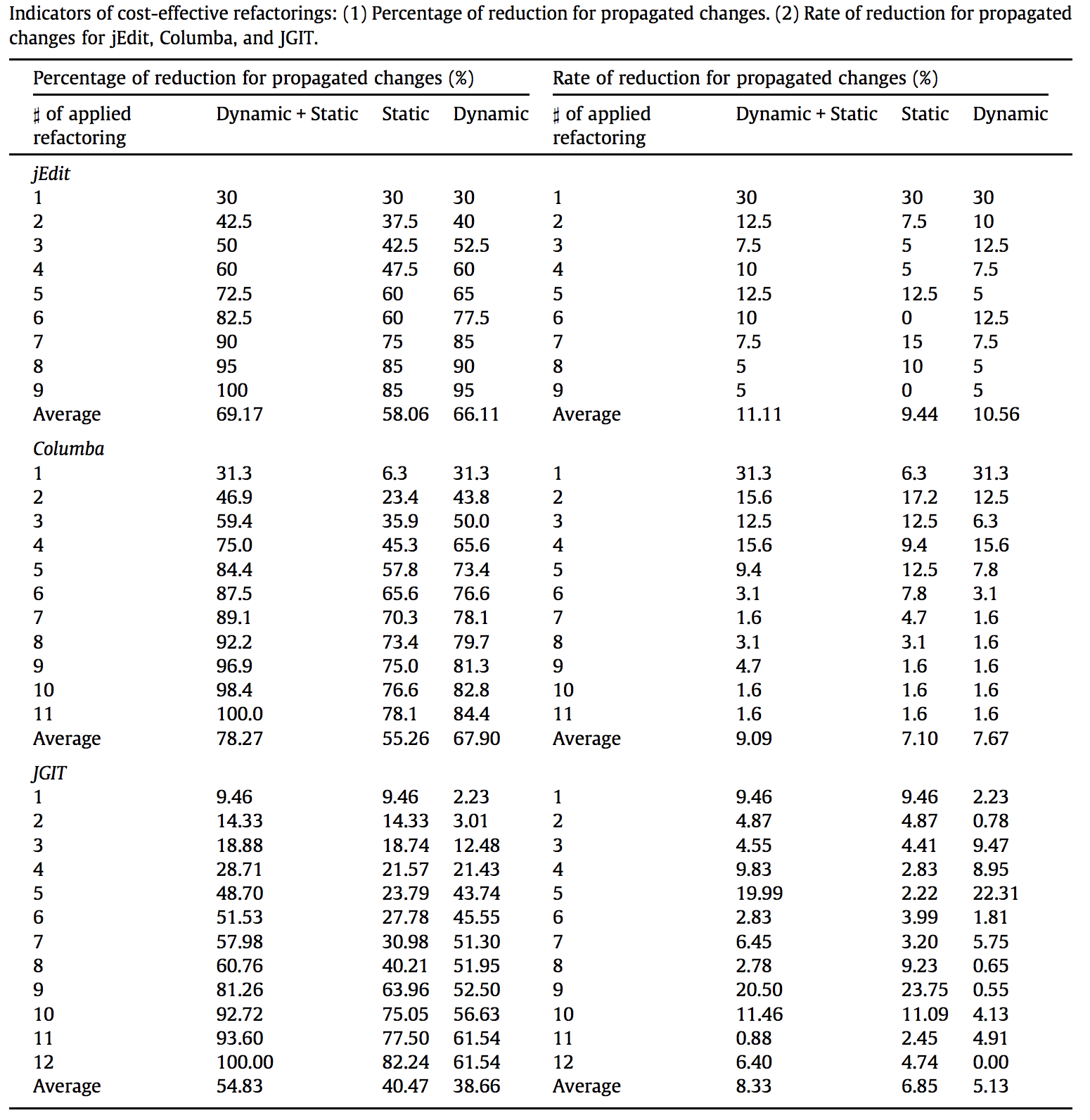 In
In Columba, the average rate of reduction for propagated changes are9.09% (Dynamic + Static),7.67% (Dynamic), and7.10% (Static). From the results in the table, we can observe that theaverage rate of reduction for propagated changesof theapproaches using dynamic information are higherthan that of the approach using only static information.
RQ2. Efficiency of multiple refactorings
Experimental design
We compare the approach of identifying multiple refactorings (our approach) with that of identifying a single refactoring at each iteration of the refactoring identification process.
| Comparators |
|---|
| - Multiple refactorings (our approach) - Single refactoring |
Evaluation measures
| Required cost to reach the final solution of maintainability metric |
|---|
| - Number of iterations - Time |
Please note that, in our paper, we defined the maintainability metric as cohesion⁄coupling because this metric produces larger fitness values as the software gets more maintainable with higher cohesion and lower coupling. In object-oriented software, high cohesion and low coupling have been accepted as important factors for good software design quality in terms of maintenance, because less propagation of changes to other parts of the system or side effects would occur. Cohesion corresponds to the degree to which elements of a class belong together, and coupling refers to the strength of association established by a connection from one class to another.
Cohesion metric:MSC (Message Similarity Cohesion)Coupling metric:MPC (Message Passing Coupling)
Results
Compared to the selection method involving single refactoring, our approach of
multiple refactoringsselects refactorings that improve the maintainability of the software design atlower computation costswith respect tosmaller number of iterationsorshorter elapsed time.
Number of iterationsto reach the final solution
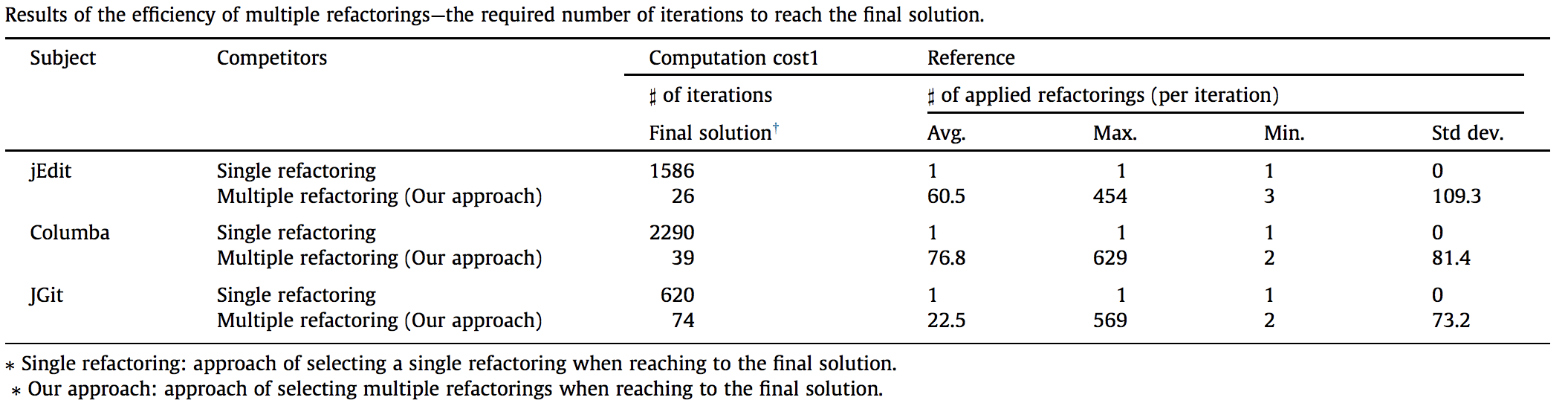
The table summarizes the results of the required costs in terms of thenumber of iterationsto reach the final solution and thenumber of applied refactorings per iterationforjEdit,Columba, andJGit, respectively. The total number of iterations required to reach to the final solution using our approach is much smaller than that required by the method of selecting a single refactoring:jEdit (26 < 1586),Columba (39 < 2290), andJGit (74 < 620).Timeto reach the final solution
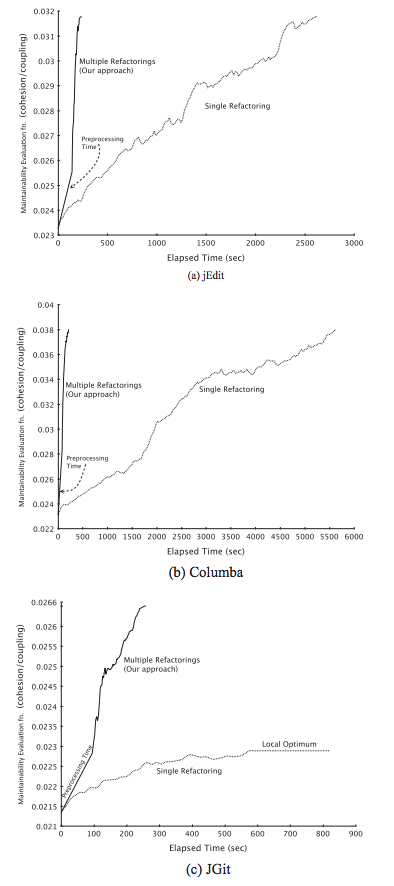
The graphs of required costs in terms of elapsedtimeto reach the final solution forjEdit,Columba, andJGit, respectively. Thex-axisshows the elapsedtime, and they-axisshows themaintainability metric. For all projects,maintainability metricof our approach increases rapidly, while that of the single refactoring approach increases comparatively slowly. Even though there is an overhead to computemaximal independent set (MIS)in the first step for the selection of multiple refactorings (denoted asPreprocessing Timein the graphs),our approach can attain the same degree of maintainability improvement at a much lower cost(i.e.,timeor thenumber of iterations). Thus, the benefit outweighs this necessary overhead.
RQ3. Efficiency of the two-phased approach
Experimental design
We compare our approach with the no-reduction approach. Our approach indicates the two-phase approach in that top 20% ranked using the Delta Table are evaluated using a fitness function (Delta top 20%). The approach to investigate all possible candidates is called the no-reduction approach.
| Comparators |
|---|
- Delta top 20% (our approach) - No-reduction approach |
The used fitness functions are MPC (Message Passing Coupling), Connectivity, and EPM (Entity Placement metric). For improving maintainability, fitness functions should be increased or decreased: MPC (-), Connectivity (+), and EPM (-).
Evaluation measures
- Efficiency of the two-phased approach
| Efficiency measures |
|---|
| - Total time - Speed up |
Speed up x means that time of Delta top 20% (our approach) is x times as fast as time of no-reduction approach. Speed up can be calculated as: Speed up = Time for no-reduction / Time for Delta top 20%.
- Performance of the
Delta Tableto find the candidates having higher fitness functions
| Performance measures |
|---|
| - Precision - Recall |
- Precision = |D ∩ E| / |D|
- Recall = |D ∩ E| / |E|
D: set of refactoring candidates in Delta Table
E: set of refactoring candidates with positive effects on each fitness function
Results
- Our approach is efficient in that it saves a considerable amount of time while still achieving the same amount of fitness improvement as the no-reduction approach. Our approach is 2.6 (min) to 13.5 (max) times faster than the no-reduction approach.
- The Delta Table perfectly identified all refactoring candidates that improved MPC. For Connectivity and EPM, more than 74% of candidates that have positive effects on each fitness function can be identified by the Delta Table.
TimeandSpeed up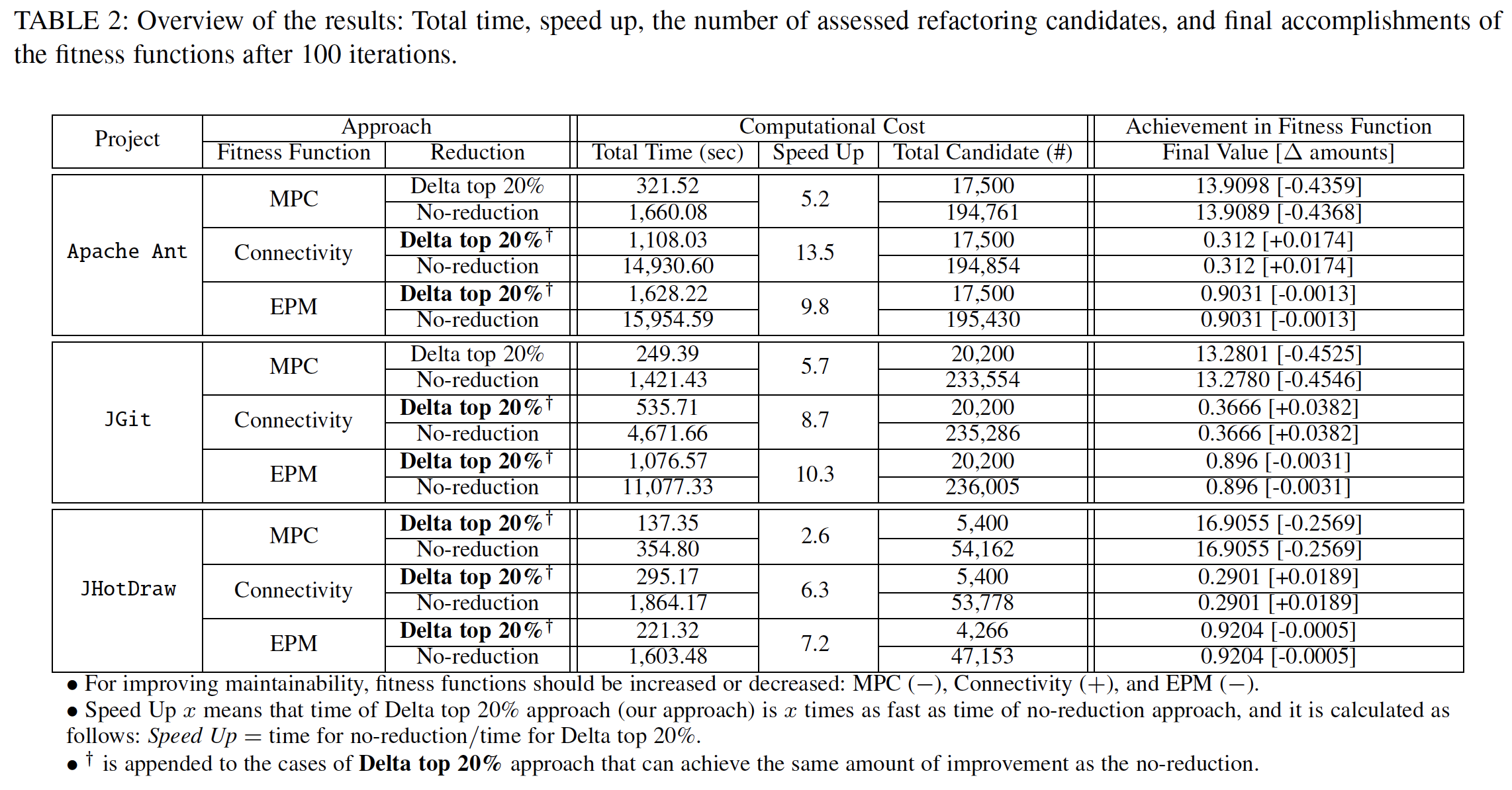
PrecisionandRecall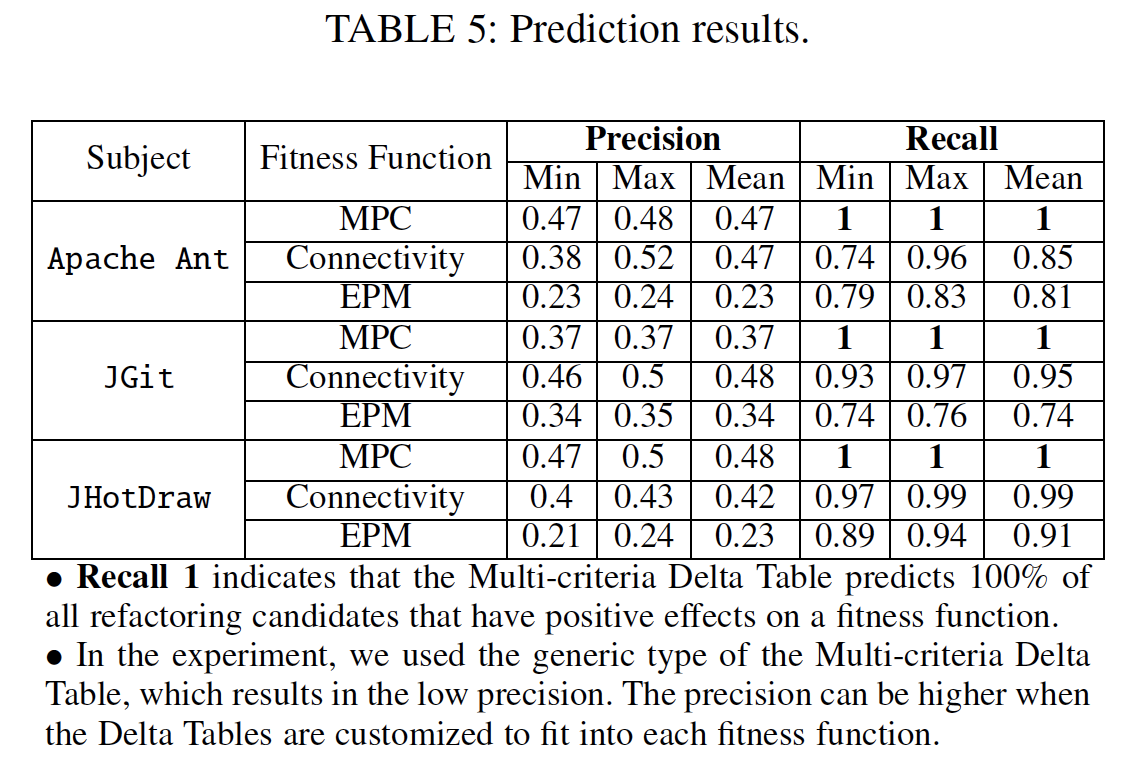
Conclusion
To improve the efficiency of the refactoring identification process, I proposed the new methods: 1) using the dynamic information, 2) selecting multiple refactorings that can be applied simultaneously, and 3) using the two-phased approach to reduce the scope of candidates to be assessed using a fitness function. The efficient refactoring identification is important for computing the large-scale software.
Papers
Two-phase Assessment Approach to Improve the Efficiency of Refactoring Identification
Ah-Rim Han, Sungdeok Cha
IEEE Transactions on Software Engineering (TSE), Online Published at July 25, 2017
[PDF] [DOI]An efficient approach to identify multiple and independent Move Method refactoring candidates
Ah-Rim Han, Doo-Hwan Bae, Sungdeok Cha
Information and Software Technology (IST), Vol. 59, pp. 53–66, Mar. 2015
[PDF] [DOI]Dynamic profiling-based approach to identifying cost-effective refactorings
Ah-Rim Han, Doo-Hwan Bae
Information and Software Technology (IST), Vol. 55, No. 6, pp. 966-985, Jun. 2013
[PDF] [DOI]
Awards and Contribution
Nov. 2014 - Apr. 2017, sole Principal Investigator, Individual Basic Science & Engineering Research Program
National Research Foundation of Korea (NRF), $125,000 [certificate] [translated version]Suggestions of Refactoring Candidates to Active Open Source
We applied the identified refactorings to the active open source project,JGit (version 4.7.1). We performed our approach of refactoring identification process automatically by choosing the refactorings that improve the maintainability of a fitness function to the greatest extent. Among the suggested refactorings, we selected to submittwo of the refactoringsfound when using the fitness function ofEPM: Move Methodcleanfrom classWindowCacheto classEntryand Move Methodcleanfrom classDfsBlockCacheto classHashEntry. The classEntryand the classHashEntryare the inner classes. The methodcleantends to access the methods and attributes in each inner class (i.e.,Feature Envydesign problems); thus, it is better to move the methods to those inner classes where those methods are actually used.
Tools
- Delta search (written in
Python)
Prototype of the two-phased refactoring identification approach: search space reduction based on theDelta Table
- Java Code Quality Analysis Tool (written in
Java) Java source code analysis and metric measurement tool